
فایل Robots.txt چیست ؟
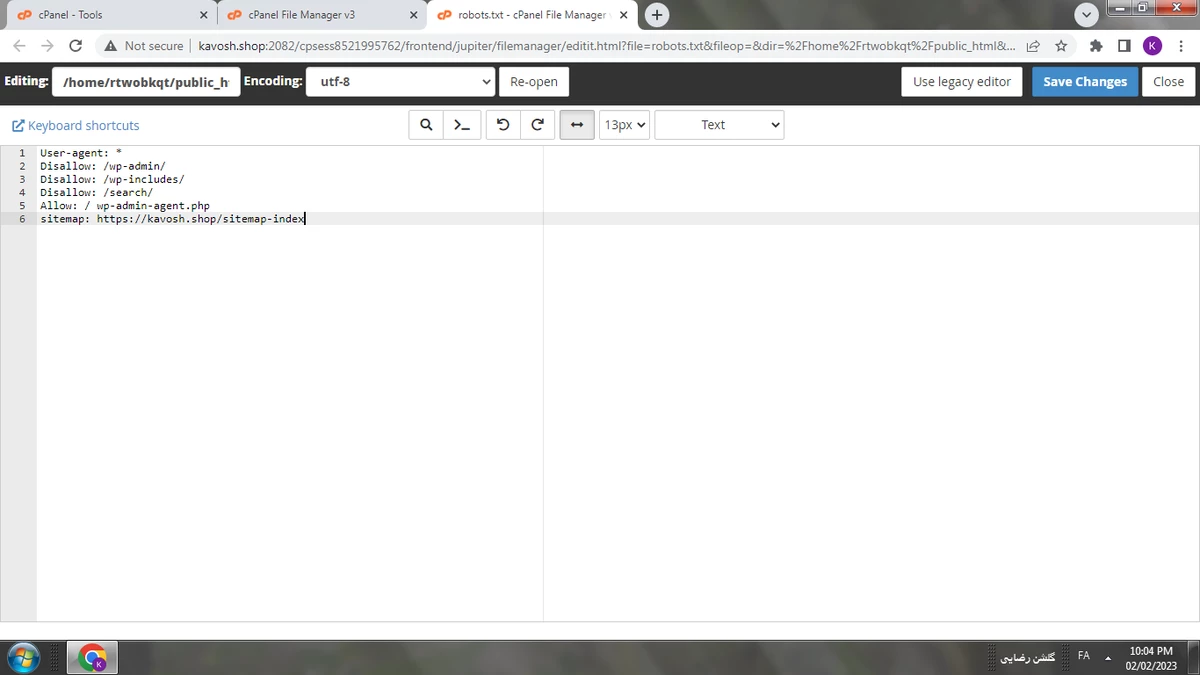
فایل Robots.txt مانند یک مجوز دهنده به ربات ها است و زمانی که ربات ها میخواهند وارد یک صفحه شوند و آن را بررسی کنند در ابتدا ان فایل Robots.txt را میخوانند . در این فایل یک سری دستورات وجود دارد که به ربات ها میگوید میتوانند وارد کدام صفحات شوند و آن ها را بررسی کنند و یا مجوز ورود به کدام صفحات را ندارد.
در واقع نقش فایل Robots.txt در وب سایت ها این است که ربات هایی را که وارد سایت میشوند راهنمایی کند .
ربات های موتور جستجوی گوگل یکی از مهم ترین ربات هایی هستند که در اینترنت گشت و گذار دارند و ممکن است در طول روز حتی چندین بار یک سایت را بررسی کنند و این تعداد دفعات بررسی بستگی به محتوایی که بارگذاری میشود و تغییراتی که به وجود می آید دارد.
در سرچ کنسول قسمتی وجود دارد به اسم Crawl Stats که تعداد دفعاتی که سایت در طول روز بررسی شده است را نشان می دهد. همچنین میتوانید در این قسمت حجم دانلود شده توسط ربات ها و مدت زمان بارگذاری صفحات را مشاهده کنید.
هرکدام از این ربات ها کار خاصی انجام می دهند. به طور مثال رباتی به اسم Googlebot که مهم ترین ربات گوگل است وظیفه اش این است که بگردد و صفحات جدیدی که در اینترنت وجود دارد را پیدا و دریافت کند و سپس این صفحات توسط الگوریتم های رتبه بندی کننده گوگل بررسی میشوند.
در هر وب سایت تعدادی صفحه وجود دارد که این صفحات دارای اهمیت یکسانی نیستند و ربات ها ممکن است به تمامی این صفحات وارد شوند. برای جلوگیری از این کار میتوانیم یک سری دستورات درون فایل Robots.txt بنویسیم که ربات ها با خواندن این دستورات متوجه شوند که اجازه ورود به کدام بخش ها از یک صفحه را دارند و یا اجازه ندارند وارد این بخش از صفحه شوند. این کار باعث می شود که سرور میزبان سایت شما الکی مشغول ربات ها نشود و به سئو تکنیکال سایت هم کمک میکند.
یکی دیگر از مواردی که به ربات ها در پیدا کردن صفحات وب کمک میکند استفاده از نقشه سایت یا sitemap می باشد. برای آشنایی بیشتر با نقشه سایت به مقاله ی sitemap چیست؟ مراجعه کنید.
در اینجا به معرفی تعدادی از دستورات مهم فایل Robots.txt می پردازیم :
۱٫ دستور User-agent : از این دستور برای مشخص کردن رباتی که دستورات برای آن نوشته شده استفاده می شود.
۲٫ دستور Disallow : از این دستور برای نشان دادن بخش هایی که ربات اجازه درخواست یا بررسی آن را ندارد استفاده می شود.
۳٫ دستور Allow : از این دستور برای نشان دادن بخش هایی که ربات مجاز به درخواست و بررسی آن می باشد استفاده می شود.
۴٫ دستور Sitemap : از این دستور برای نشان دادن آدرس فایل نقشه سایت به ربات ها استفاده می شود.
در ادامه توضیح می دهیم که چطور باید از این دستورها استفاده کنیم
- مشخص کردن ربات با دستور User-agent
این دستور برای مشخص کردن ربات خاصی است و می توان به دو روش از آن استفاده کرد.
یکی اینکه اگر بخواهیم به همه ی ربات های خزنده گوگل دستور یکسانی دهیم باید بعد از User-agent علامت (*) ستاره را بذاریم که این علامت به معنای << همه چیز >> می باشد. به عنوان مثال : *:User-agent
این دستور به این معنی است که دستورهای بعد برای همه ی ربات های جستجو است.
ولی اگر بخواهیم فقط به یک ربات خاص مثل ربات گوگل ( Googlebot) دستور خاصی را دهیم باید دستور را به این شکل بنویسیم :
User-agent: Googlebot
۲ . مشخص کردن صفه ها و قسمت های غیر مجاز با استفاده از دستور Disallow
این دستور برای این منظور استفاده می شود که به ربات ها بفهماند که نباید کدام بخش ها از سایت را بررسی کنند و بیانگر آدرس هایی می باشد که باید از ربات جستجو پنهان بمانند.
مثلا اگر نخواهیم موتور جستجو پوشه ی Photo را ایندکس کند باید دستوری به این شکل بنویسیم :
*:User-agent
Disallow:/Photo
به این نکته توجه کنید که لزومی ندارد که حتما آدرس را به طور کامل در مقابل دستور Allow یا Disallow بنویسید.
۳ . مشخص کردن قسمت های مجاز برای ربات ها با استفاده از دستور Allow
با نوشتن این دستور ربات های گوگل متوجه می شوند که اجازه دسترسی به کدام قسمت های سایت را دارند.مثلا عکسی در پوشه Photo که در مثال قبل به آن اجازه دسترسی ندادیم وجود دارد و الان میخواهیم که ربات فقط به این عکس از آن پوشه دسترسی داشته باشد برای این کار دستور زیر را مینویسیم :
*:User-agent
Disallow:/photo
Allow:/photo/kavosh.jpg
این دستور به ربات می گوید درست است که پوشه photo از دسترس خارج شده ولی اجازه دیدن و ایندکس کردن فایل kavosh.jpg را دارد.
۴ . نقشه سایت
گوگل برای صاحب وب سایت ها راه های مختلفی برای دسترسی به نقشه سایت گذاشته است که بهترین آن استفاده از ابزار سرچ کنسول است.
معرفی تعدادی از ربات های گوگل :
• AdSense : رباتی است که صفحات را بررسی میکند و هدفش نمایش تبلیغات مرتبط با صفحه است.
• Googlebot Image : رباتی است که عکس ها را پیدا و بررسی میکند.
• Googlebot News : رباتی است که سایت های خبری را ایندکس میکند.
• Googlebot Video : رباتی است که ویدیو هارا بررسی میکند.
• Googlebot : رباتی است که صفحات وب را کشف و ایندکس میکند و دارای دو نوع Desktop و Smartphone می باشد.
دلیل اهمیت فایل Robots.txt ؟
فایل Robots.txt به چند دلیل دارای اهمیت می باشد :
- مدیریت ترافیک ربات ها به وب سایت
مدیریت ترافیک ربات ها از این نظر دارای اهمیت می باشد که سرور میزبان وب سایت شما برای بارگذاری و پردازش صفحات برای ربات ها مشغول نشود زیرا بیشتر سرورها و میزبان های وب سایت از نظر ترافیک و پهنای باند دارای محدودیت می باشند و به این علت است مصرف ترافیک برای ربات ها به صرفه نیست.
۲٫ جلوگیری از نمایش فایل ها یا صفحات در نتایج جستجوی گوگل
اگر در فایل Robots.txt دستوری بنویسید که ربات های گوگل مجوز دسترسی به تعدادی از صفحات را ندارند این صفحات اصلا بررسی نمی شوند ولی هیچ تضمینی برای نمایش این صفحات در نتایج جستجوی گوگل وجود ندارد. زیرا این امکان وجود دارد که ربات ها با دسترسی به لینک هایی که به همان صفحات مربوط می شود و با کمک انکر تکست، لینک آن صفحات را ایندکس کنند. بهترین راهی که در حال حاضر میتوان از آن برای حذف صفحه ای از نتایج گوگل استفاده کرد افزودن دستور noindex به قسمت head این نوع از صفحات است. در وردپرس تعدادی افزونه برای این کار وجود دارد.
۳٫ مدیریت Crawl Budget
هرچقدر تعداد صفحات یک سایت بیشتر باشد قاعدتا ربات های موتور جستجوی گوگل مدت زمان بیشتری صرف خزیدن و ایندکس کردن صفحات می کنند و همین مدت زمان بیشتر باعث تاثیر منفی روی رتبه سایت در نتایج گوگل می شود.
حالا چرا این اتفاق رخ می دهد ؟ به این دلیل که ربات خزنده گوگل (Googlebot) یک ویژگی به اسم Crawl Budget دارد.
این Crawl Budget در واقع تعداد صفحه هایی از وب سایت است که ربات های گوگل در طول یک روز آن ها را خزیده و بررسی می کنند. تعداد این صفحه ها که Googlebot مشاهده می کند بر اساس حجم وب سایت که بستگی به تعداد صفحات دارد و سلامت آن که عدم بروز خطا می باشد و تعداد بک لینک هایی که در وب سایت وجود دارد تعیین می شود.
در واقع Crawl Budget دارای دو بخش می باشد که یکی از آن ها Crawl Rate Limit یا همان حد نرخ خزیدن و دیگری Crawl Demand می باشد.
در ادامه به توضیح هرکدام می پردازیم :
Crawl Rate Limit
ربات گوگل یا همان Googlebot طوری طراحی شده است که یک شهروند خوب برای دنیای اینترنت باشد و اولویت اصلی این ربات خزیدن است و به همین دلیل جوری طراحی شده که بر تجربه کاربری بازدید کنندگان سایت تاثیری نگذارد. به این نوع بهینه سازی Crawl Rate Limit گفته می شود که برای ارائه ی تجربه کاربری بهترتعداد صفحه هایی را که در یک روز قابل Crawl است را کم می کند.
خلاصه اینکه Crawl Rate Limit نشان دهنده تعداد دفعات ارتباط همزمان ربات گوگل با یک وب سایت در کنار تعداد دفعات توقف این ربات در عملیات خزش یا Crawling یک سایت است. نرخ خزش یا همان Crawl Rate بر اساس چند عامل می تواند تغییر کند :
• سلامت خزش (Crawl Health ) : اگر یک وب سایتی سریع باشد و توانایی پاسخ دهی سریع به سیگنال ها را داشته باشد مطمئن باشید که Crawl Rate بالا می رود ولی اگر سایتی کند باشد و یا هنگام Crawl خطایی از سرور وجود داشته باشد نرخ خزش ربات گوگل کاهش پیدا می کند.
• تعیین محدودیت در Search Console Google : صاحبان وب سایت ها می توانند میزان خزش وب سایت شان را کاهش دهند.
Crawl Demand
در صورتی که ربات گوگل به حد Crawl Rate که تعیین شده نرسد و درخواستی برای ایندکس شدن نباشد ربات گوگل فعالیت کمی خواهد داشت. دو تا از فاکتور هایی که نقش مهمی در تعیین یا تقاضای خزش دارند در زیر آمده اند :
• محبوبیت : آدرس هایی که در اینترنت از محبوبیت بیشتری برخوردار هستند بیشتر از آدرس های دیگر خزیده می شوند و این کار باعث می شود تا در ایندکس گوکل تازه تر باشند.
• بیات شدن ( Staleness ) : گوگل به شیوه ای آدرس ها را ذخیره می کند که از قدیمی شدن آن ها جلوگیری شود.
عوامل و فاکتورهایی که از نظر گوگل روی عملیات خزش و ایندکس شدن سایت تاثیر منفی دارند :
• وجود محتوای تکراری در سایت
• وجود صفحات خطا
• وجود ناوبری ضعیف در سایت
• محتوای بی ارزش و اسپم
• صفحات حک شده در وب سایت
بررسی میزان بودجه خزش در سایت
هر سایتی یک سهمیه ای از ربات های گوگل دارد و ربات های گوگل توانایی این که تمام صفحات سایت را به طور یکسان خزش و ایندکس کنند ندارد به همین دلیل یک بودجه برای خزش در آن سایت در نظر می گیرند و این موضوع از نظر سئو مهم است زیرا اگر گوگل صفحه ای را ایندکس نکند آن صفحه رتبه ای در موتور جستجو ندارد. این اتفاق بیشتر برای سایت هایی می افتد که دارای شرایط زیر هستند:
- سایتی که بزرگ باشد : به این معنی که در طول روز صد صفحه جدید به آن افزوده شود در این صورت با مشکل ایندکس مواجه می شود.
- سایتی که تازه تعداد زیادی صفحه به آن اضافه شده باشد : یعنی یک قسمت جدید که به تازگی به سایت اضافه شده است و دارای تعداد صفحات زیادی می باشد. در این صورت باید بررسی کنید که آیا بودجه کافی برای خزش دارید صفحات می توانند ایندکس شوند یا نه .
- سایتی که ریدایرکت های زیادی دارد : وجود ریدایرکت در سایت می تواند باعث نابود شدن بودجه خزش شود.
چگونه نرخ بودجه خزش را افزایش دهیم :
- بهبود بخشیدن سرعت سایت : سرعت سایت برای گوگل اهمیت بالایی دارد و این یعنی هرچقدر که سرعت وب سایت بالاتر باشد ربات های گوگل می توانند تعداد صفحات بیشتری از سایت را بخزند. اگر سرعت سایت کند باشد ربات ها باید وقت بیشتری برای خزش صرف کنند ولی زمانی که سرعت بالا باشد ربات ها تعداد صفحات بیشتری را خزش می کنند.
- استفاده از لینک های داخلی : از نظر ربات های گوگل صفحاتی که تعداد لینک های داخلی و خارجی بیشتری دارند با ارزش تر هستند . اهمیت لینک های داخلی بیشتر است زیرا میتوانند تا حدودی نبود لینک های خارجی را جبران کنند زیرا این لینک ها ربات ها را به صفحات مختلف هدایت می کنند و آن ها را مجبور به ایندکس کردن می کنند.
- نادیده نگرفتن صفحات یتیم ( Orphan Pages ) : صفحات یتیم به صفحاتی گفته می شود که لینک داخلی به صفحات دیگر ندارند و هیچ لینک خارجی هم به آن ها داده نشده به همین دلیل پیدا کردن اینگونه صفحات برای ربات های گوگل به شدت سخت می باشد. برای اینکه از بودجه خزش سایت درست استفاده شود باید از لینک های داخلی و خارجی صفحات سایت مطمئن شوید.
- محدود کردن محتواهای تکراری : به دلایل مختلفی باید محتواهای تکراری را محدود کنیم . اولین دلیل که مهم نیز می باشد این است که اینگونه از محتواها بودجه خزش سایت را نابود می کنند و باعث دردسر می شوند پس باید صد در صد محتوای سایت با کیفیت و منحصر به فرد باشد.
کارهایی که باعث بهینه شدن میزان بودجه خزش در وب سایت می شوند :
- بررسی کردن URL های نامتعارف سایت : URL های نامتعارف به پارامترهایی گفته میشود که بر اثر فیلتر کردن یا جستجو به URL یک صفحه خاص اضافه شده است. این پرامترها کاربردی هستند ولی میتوانند برای کراول و ایندکس کردن صفحات مشکل ایجاد کنند. این مشکلات بیشتر درباره ی سایت های فروشگاهی صدق میکنند و افرادی که سایت های فروشگاهی دارند باید راهی برای جلوگیری از هدر رفتن بودجه خزش سایت خود پیداکنند. برای این کار فقط باید به گوگل بگویید که دوست ندارید صفحات سایت شما ایندکس و کرال شوند. میتوانید دو روش را امتحان کنید:
- برای کرال نشدن باید در فایل txt پارامتر درج کنید.
- از کد نویسی و تگ Noindex در صفحات استفاده کنید.
- شناسایی لینک های شکسته : اگر لینک های شکسته را رها کنید می توانند بودجه خزش سایت را محدود کنند. لینک شکسته به لینکی میگویند که ربات ها و کاربران را به صفحاتی ببرد که دیگر نیستند. برای حل این مشکل باید لینک های شکسته را شناسایی و آن ها را پیدا کنیم. Ahrefs یک ابزار آنلاین می باشد که در این کار به شما کمک میکند.
- سایت مپ را مجدد بررسی کنید : یکی از کارهایی که برای بهینه سازی بودجه خزش سایت انجام می شود بازدید مجدد از سایت مپ است و بهتر است که این کار را با هدف بیشتر کردن صفحات سالم انجام دهید. برای این کار یک لیست از صفحه هایی که ریدایرکت هستن و خطا ی ۴۰۴ دارند و یا لینک هایی که شکسته هستند بنویسید از این طریق میتوانید URL ها را از سایت مپ حذف کنید.
- محتواهای تکراری را شناسایی کنید : محتواهای تکراری یا Duplicate Content ها نیز میتوانند برای بودجه خزیدن سایت مشکل ایجاد کنند به این صورت که صفحه هایی که دارای محتوای تکراری و یا شبیه به هم هستند باعث می شوند که ربات ها گیج شوند و در برخورد با اینگونه صفحات فکر کنند که قبلا این صفحه را کرال کرده اند و از آن عبور کنند. ابزار Ahrefs در اینجا می تواند برای شناسایی محتوای تکراری به شما کمک کند.
- بهبود زمان بارگذاری صفحات : مدت زمان بارگذاری صفحه می تواند نقش مهمی در افزایش بودجه خزش یک سایت داشته باشد به همین دلیل باید سرعت بارگذاری سایت را افزایش دهیم.
کندی بارگذاری سایت چطور باعث پایین آمدن بودجه خزش می شود ؟
هنگامی که کاربر وارد یک سایت می شود مدتی طول میکشد تا صفحه به صورت کامل برای او نمایش داده شود . در واقع یک تایم استاندارد وجود دارد که باید در آن تایم محتوای صفحه برای کاربر نمایش داده شود و اگر سایتی کند باشد وقتی کاربر وارد شود محتوا برایش نشان داده نمی شود و او از سایت خارج میشود. همین اتفاق برای ربات های موتور جستجوی گوگل نیز می افتد و باعث می شود که ربات بودجه خزش کمی را برای سایت در نظر بگیرد . برای رفع این مشکل در سایت های وردپرسی میتوانید از پلاگین ای افزایش سرعت استفاده کنید و در غیر این صورت از دولوپر کمک بگیرید.
- صفحات سالم را افزایش دهید ( ۲۰۰ ok ) : مهم ترین معیار افزایش درصد کرال صفحه هایی است که در مقابل (۲۰۰) ok نوشته شده اند زیرا این گزینه نشان دهنده ی کرال موفق صفحات سالم سایت است وهرچقدر که این عدد به ۱۰۰% نزدیک تر باشد سایت سلامت تر است . برای افزایش کرال صفحات سالم باید به صفحه هایی برویم که کرال آن ها با مشکل روبه رو شده است و تا جایی که می توانیم ارور هایی را که دریافت میشود را کاهش دهیم.
- محتواهای قدیمی و بی کیفیت را بهینه سازی کنید : برای بهبود محتوای قدیمی سایت باید یک برنامه ریزی داشته باشیم و هر چند وقت یکبار سری به محتوای قدیمی سایت بزنیم و در راستای بهبود آنها تلاش کنیم همچنین می توانیم بر روی محتواهای بی کیفیت سایت نیز تغیراتی انجام دهیم و آن ها را بهتر کنیم.
- لینک سازی داخلی : لینک سازی داخلی این فرصت را به ربات های خزنده می دهد که به تمامی صفحات سایت دسترسی داشته باشند. لینک سازی و پیوند دادن بین صفحات سایت باعث بهبود نرخ خزش می شود.
آیا نوشتن فایل Robots.txt ضروری است؟
نوشتن فایل Robots.txt ضرورتی ندارد ولی توصیه میشود که برای بهبود سئو سایت همیشه از این فایل استفاده شود زیرا این فایل ضرری برای وب سایت ندارد بلکه میتواند مفید نیز باشد و شرایطی را به وجود آورد که بتوانید دستورات مورد نیاز برای خزیدن موتورهای جستجوی گوگل را در سایت خود نگه دارید تا موتورها بتوانند همیشه به این فایل دسترسی داشته و از آن برای بهینه سازی جستجو و خزیدن در وب سایت استفاده کنند که این خود میتواند نتایج خوبی را برای وب سایت به همراه داشته باشد.



دیدگاهتان را بنویسید